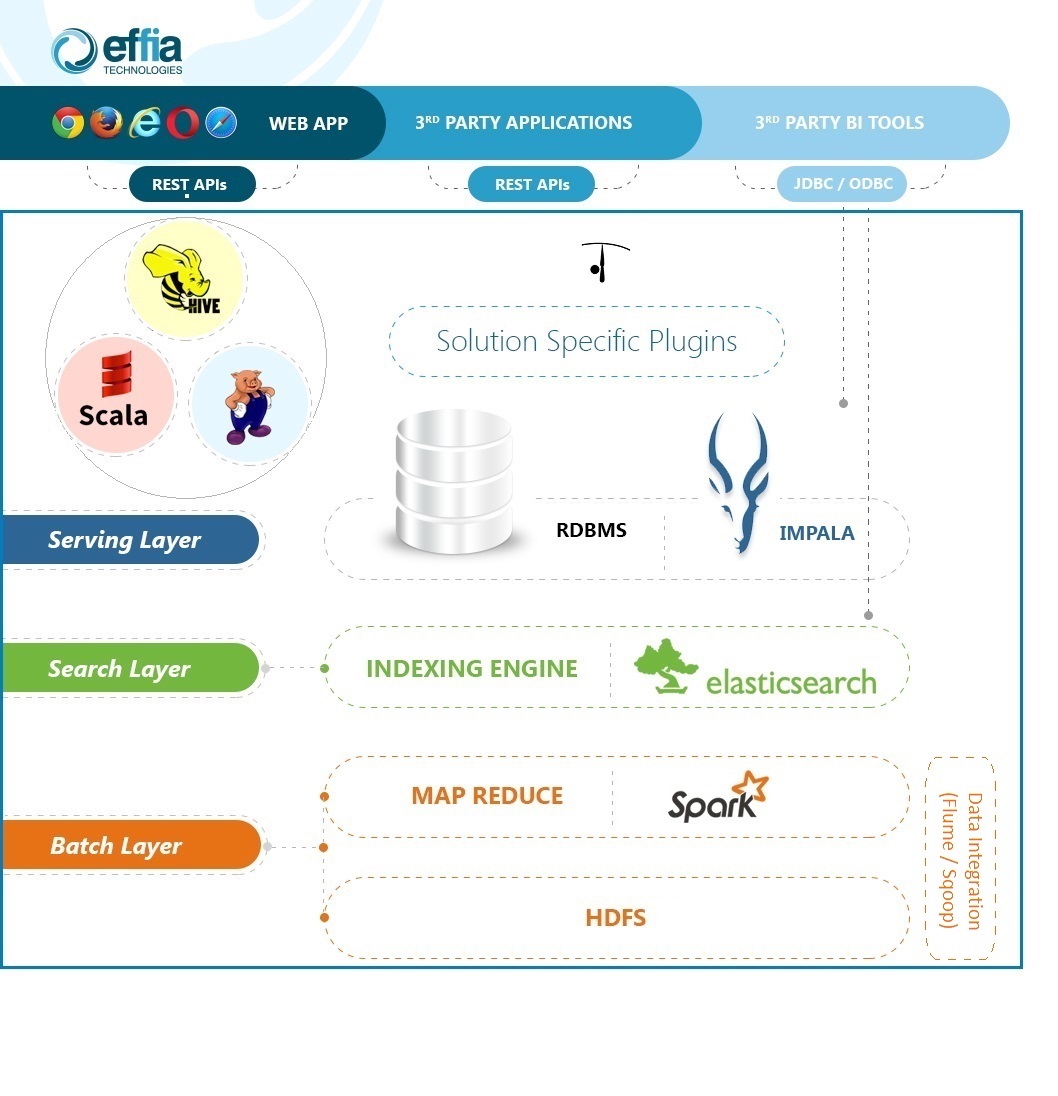
eARQUERO uses various components of Hadoop plus other Hadoop based technologies.
Hadoop evolved into a complex collection of very powerful tools and platforms. Collectively,
they provide unparalleled storage and processing capabilities.
Batch layer
Contains all the technologies for analyzing massive amount of data and real time
data using batch oriented approach.
Search Layer
This is the layer responsible for data indexing and it provides the fundamental
search based data discovery feature.
Serving Layer
It is meant to provide a quick data access (near-real-time query access) to multiple
concurrent users/applications.
eARQUERO is classically organised in a client/server relationship. The user interface
is a HTML5/javascript based rich client running into the browser which talks to
the server through a set of REST based APIs (JSON/HTTP). So, all the product functionalities
are exposed as REST APIs as well as through a user interface.